빅데이터의 시초 : GFS
- Google File System 논문 (2003년)
- 막대한 양의 웹 문서를 저장 조회해야 하는데, 컴퓨터 1대로는 당연히 처리가 불가능.
- 저렴한 하드웨어를 사용하면서, 대신 중복 저장을 통해 파일 유실을 방지.
- 파일을 새로 추가하는데 집중, 삭제나 파일 덮어쓰기는 어려움.
- Latency보다 Throughput을 중시
- 클러스터 댓수를 늘릴수록 저장용량과 throughput이 점점 올라감.
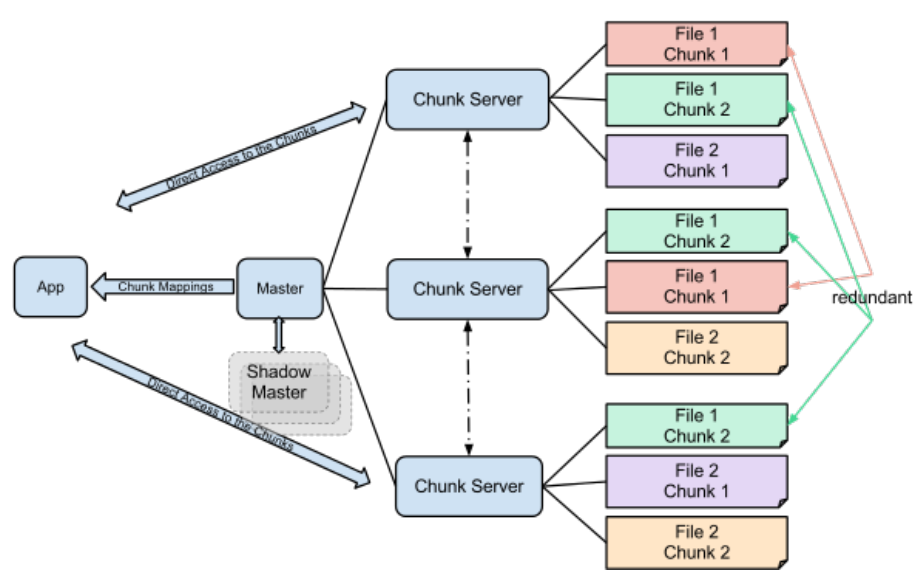
- 여러대의 Chunk Server에 중복저장
- Master를 통해 파일의 위치를 알아내고, Chunk Server에 직접 접속해서 데이터 전송받음
빅데이터의 시초 : MapReduce
- Google Reduce(2004 논문)
- 여러대의 분산 저장소에 존재하는 데이터를 변환하거나 계산하기 위한 프레임워크
- Functional Programming의 Map() 함수와 Reduce() 함수를 조합하여 효율적으로 분산 환경에서 다양한 계산을 함.
- Map() : A인 데이터를 B로 변환시키는 계산을 리스트에 대해 수행
- List(1,2,3).map(x=> x*2) // result: List(2,4,6)
- Reduce() : 리스트에 들어 있는 A, B, C를 특정 룰에 의해 합치는 작업
- List(1,2,3).reduce((a,b,) => a+b) // result
- Map()과 Reduce()를 조합하면 다양한 작업을 수행할 수 있음.
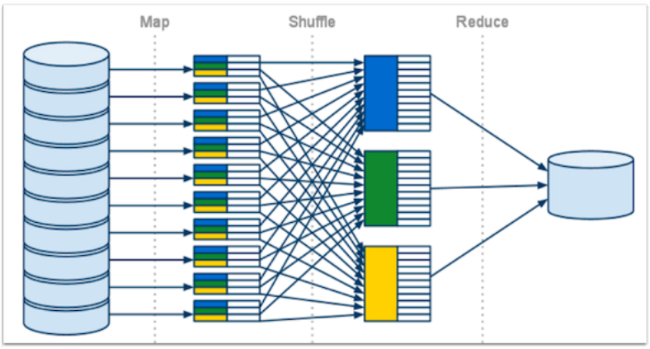
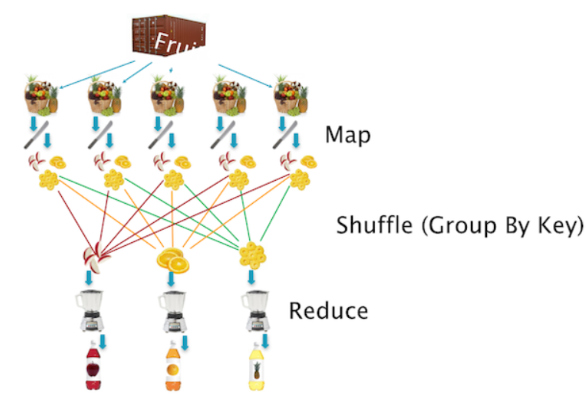
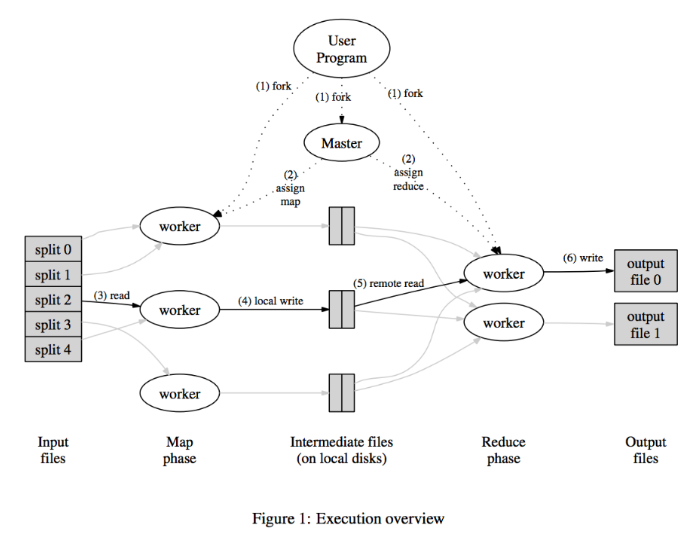
- Input 파일을 잘게 나눠서 여러 worker에서 나눠서 Map() 작업 수행
- 중간파일을 저장한후, 이를 병합해서 Reduce() 작업 실행
- Reduce()를 수행한 워커에서 각각의 결과물을 저장