데이터 저장소
- 데이터를 파일로 그대로 저장하는 방법
- Hadoop HDFS 사용
- HDFS의 대안은 많지는 않음. MapR File System정도가(유료) 있음
- 데이터베이스를 사용하는 방법
- HBase등의 분산 데이터베이스들
- 고전적인 RDBMS와 분산 데이터베이스를 혼용하기도 함
Hadoop HDFS
- HDFS (Hadoop Distributed File System)
- 구글의 GFS논문의 오픈소스 구현체
- Block단위로 파일을 보관 (Block: 64MB)
- Block을 여러 노드에 나누어서 보관 (3 Replica가 기본), 노드 장애시 장애를 내지 않고 대응가능
- 자체적으로 중복저장과 장애복구 기능을 가지고 있기에, 값비싼 서버용 장비가 아닌 PC급 장비를 활용하여 비용을 낮출 수 있음
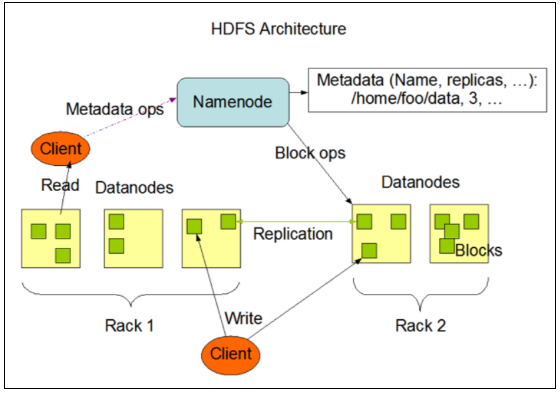
- 다양한 접근 옵션을 제공
- Java API
- FS Shell
- DFS Admin
- 웹 인터페이스
- HDFS Shell Api
- 로컬파일 복사
- hdfs dfs -copyFromLocal temp.txt /
- 목록보기
- 로컬로 파일 복사
- hdfs dfs -copytoLocal /temp.txt
- 디렉토리 만들기
Apache HBase
- 수많은 데이터에 대한 Random, Real time 엑세스를 제공
- 빠른 속도
- 데이터 요청에 대해 실시간으로 응답
- 메모리 캐쉬기능
- 편리한 사용성
- 높은 내구성
- 데이터를 네트워크에 중복저장
- Strong consistent 제공
- 자동 장애복구
- 자동으로 샤딩, 로드밸런싱
- 컬럼기반 데이터베이스
- 기존의 로우 기반 (Row Oriented) 데이터베이스에 비해, 스키마가 자유 롭고 Sparse한 거대한 테이블에 적합
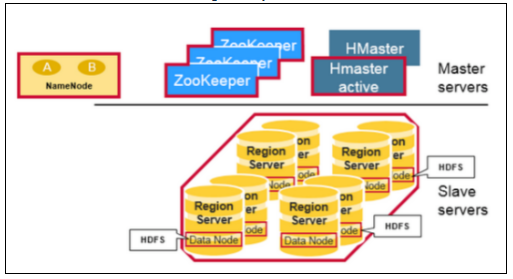
- HBase 아키텍처
- Master-Slave 구조, 데이터들이 Region (Key-value 를 영역에 따 라 나눈 단위) 의 형태로 저장되어있음
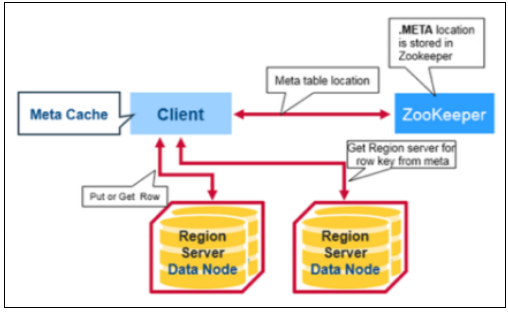
- META 테이블을 가지고 있는 region 서버를 ZooKeeper를 통해 알아 냄
- META 테이블에서 조회를 원하는 row key 를 가지고 있는 region 주 소를 조회 후
- 해당 region 서버에서 데이터를 조회
데이터 수집기
- 많은 경우에는 서버에서 남기는 로그를 수집하게 됨
- 클라이언트 앱 등에서 로그를 남기는 경우에도 서버에서 수합해서 로그를 남기는 구조
- 웹사이트를 크롤하는 경우나, 센서 혹은 SNS에서 데이터를 모으는 경우 에도 유사한 구조를 가짐
- 빅데이터
- 여러대의 서버에서 수많은 로그를 남기고 있을 것이고, 이 를 효과적으로 수합하여 처리하는 도구들이 필요
- 다양한 소스와 출력을 지원하며, 성능과 안정성이 중요
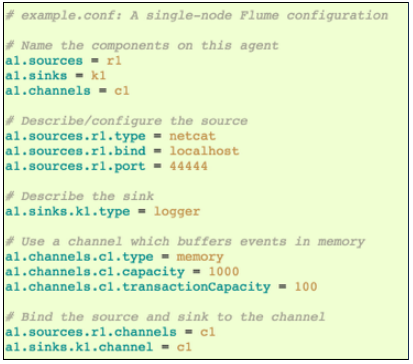
Apache Flume
- Flume (물미끄럼틀)
- 매우 단순한 구조로, 몇가지 설정만으로 구동할 수 있음
- Source, Channel, Sink 구조
- Hadoop HDFS와 HBase를 위해 만들어짐
- 실행하기
- bin/flume-ng agent -n $agent_name -c conf -f conf/flumeconf.properties.template
- 설정예시
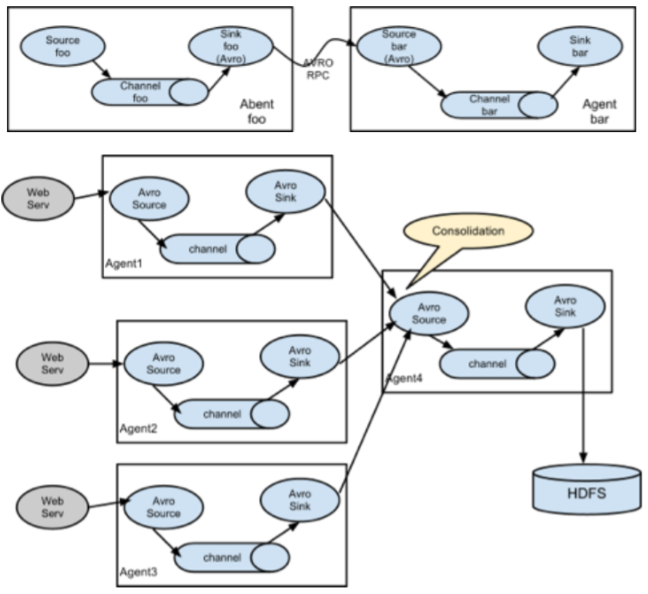
- 다양한 구성이 가능
Apache Kafka
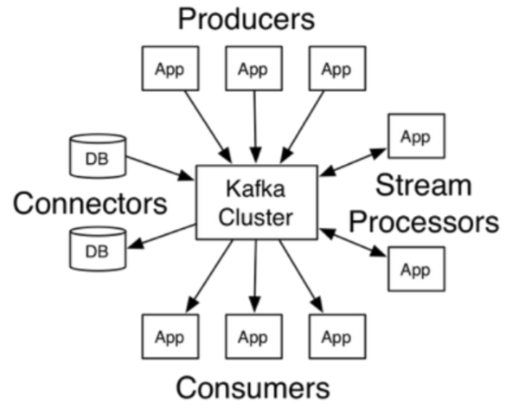
- 분산 처리가 가능한 고성능 메세지 큐
- Flume는 push 방식, Kafka는 pub/sub 방식
- 메세지를 디스크에 저장하여 유실없이 처리가 가능하며, 다양한 응용이 가능
- Flume는 여러가지 collector를 제공하지만 Kafka는 메세징만을 제공하므로 직접 구현해야 함
{"serverDuration": 328, "requestCorrelationId": "d82af8364928f4f2"}