Why Kafka?
- 빠르다
- 분산형 메시지 처리와 관련된 시스템들이 Kafka 이전에도 Active MQ와 같이 다양하게 존재해왔다.
- 이런 분산형 시스템들에 비해서 Kafka 시스템이 갖는 강점은 빠른 데이터 처리에 있다.
- 여러 이유가 있을 수 있겠지만, Kafka를 최초로 개발한 LinkedIn 팀에서 기존 Messaging system의 문제점을 분석하고 이를 개선하기 위해 어떤 부분이 시스템의 핵심이 되어야하는지, 그 맥락을 잘 집었다고 볼 수 있겠다.
- Publish & Subscribe 모델 지원
- 앞서 언급한 데이터 활용 모델을 구현하기 위해서는 메시징 시스템이 Publish & Subscribe 모델을 지원해주는게 최선이다.
- 지원하지 않는다면 따로 이 부분을 구현해야하는데 데이터의 연속성 보장등을 어플리케이션에서 단독으로 보장하기에는 많은 무리수가 있다.
- Topic을 기반으로 Kafka가 이 부분에 대한 강력한 뒷배경이 되어준다.
- 잠깐 다운되도 된다
데이터를 처리하는 Consuming 시스템의 입장에서 다운타임은 운영적 관점에서 치명적인 시간이된다.
하지만 Kafka 역시 분산형 메시지 시스템들이 공통적으로 지원하는 메시지 보관 기능을 마찬가지로 지원한다.
다만 언제까지고 데이터를 보관해주지는 않는다.
시스템 단위에서 설정된 보관 시간이 존재하고, 해당 시간 이내의 데이터는 분산환경내에 보관된다.
Topic and Partitions
- Topic
- Kafka에서 데이터에 대한 논리적인 이름이다. Kafka를 통해 유통되는 모든 데이터는 Topic이라는 데이터 유형으로 만들어지며 Producer/Consumer들은 자신이 생성 혹은 소비할 Topic의 이름을 알고 있어야만 한다.
- Partition
- Topic을 물리적으로 몇 개의 분할된 Queue 형태로 나눠 관리할지를 지정한다.
- 특정 Topic이 1개의 Partition으로 되어 있다는 것은 데이터 처리를 위한 Queue가 한개 존재한다는 것이다.
- 3개의 Partition으로 구성되어 있다면 3개의 Queue가 존재하고, 각각의 Queue에는 독립적으로 데이터가 들어갈 수 있다.
- 이론적으로 Partition의 개수가 많을수록 동시에 클러스터에 데이터를 더 빠르게 받아들일 수 있음을 의미한다.
- 하지만 과하면 망한다는거… 따라서 클러스터를 구성하는 서버, CPU/Core, Memory 등 Resource의 제약을 고려해서 최적의 Partition 정책을 세우는게 필요하다.
- Kafka내의 메시지/데이터는 모두 Topic이라는 이름을 통해 유통된다.
- 그리고 이 유통 과정에서 성능이 제대로 나게 할려면 시스템에 걸맞는 Topic별 Partition 정책을 어떻게 가져가야할지를 잘 판단해서 결정하는게 필요하다!
- 메시지 큐의 일종이다.
- 분산형 스트리밍 플랫폼이다.
- 대용량의 실시간 로그처리에 특화 되어 있다. 기존 범용 메시징시스템에 비해 TPS가 매우우수 하다.
- 메시지를 파일시스템으로 관리하여,재시작으로 인한 메시지 손실 우려를 감소한다.
- 자신의 처리 능력만큼만 처리하므로, 최적의 성능을 낼 수 있다.
기존메시징 시스템과 비교
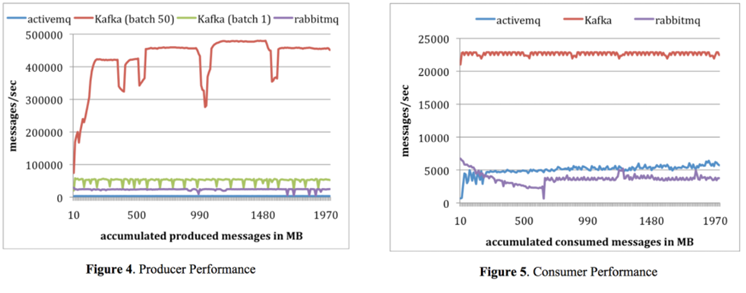
카프카의 관리 방식
ZooKeeper가 카프카의 상태와 클러스터 관리를 해준다.
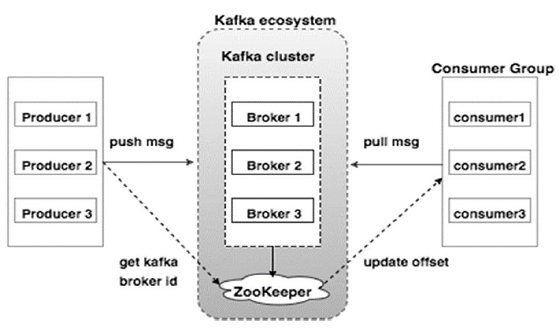
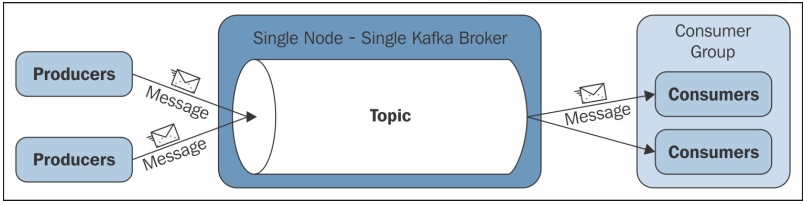
정해진 topic 에 producer 가 메세지를 발행 해 놓으면 consumer 가 필요할때 해당 메세지를 가져간다.
2 Comments
Anonymous
Anonymous
Add Comment