| Table of Contents |
|---|
| Info | ||
|---|---|---|
| ||
Autoscaling이란?
- Application의 확장 → pod scaling
- 효율적인 Container 운영
- 지속적으로 변하는 사용자 workload 처리
가. HPA (Horizontal Pod
...
Autoscler)
가-1. HPA 개요
- Pod replica의 갯수를 변경하여 scaling.
- CPU와
...
- memory의 metrics를 base로 하여 scaling을
...
- trigger.
- Multiple metrics, Custom metrics,
...
- external metrics를
...
- base로 사용하는 것도 가능
...
- .
가-2. HPA Workflow
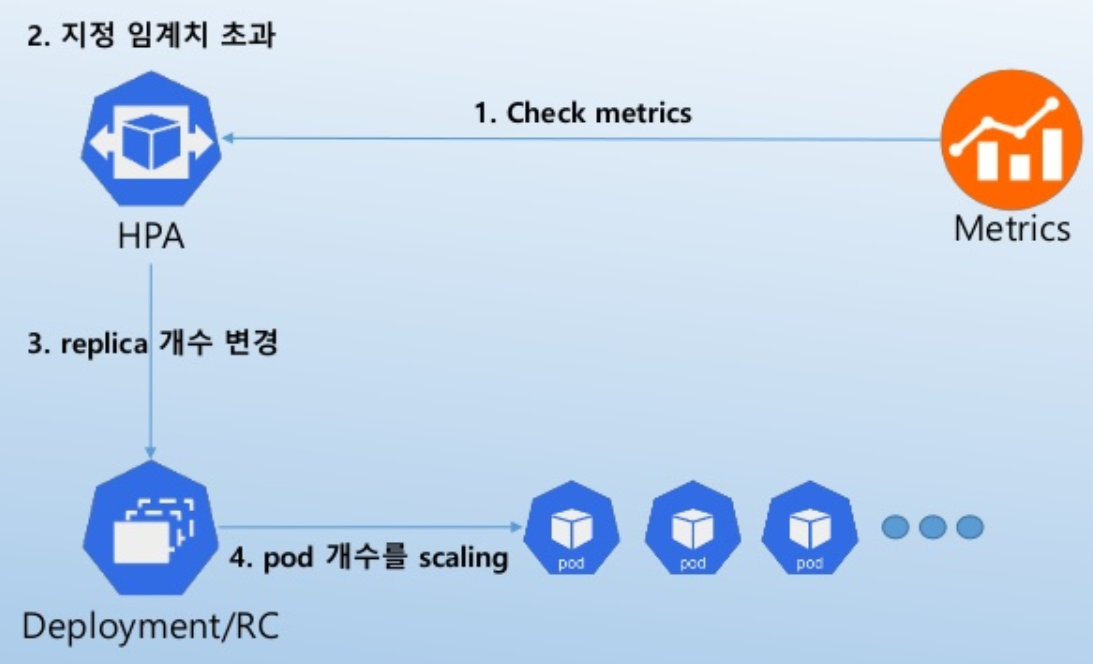
가-3. HPA에 대하여 알아야 할 것들
- 기본 HPA sync 주기는 30초.
→ controller manager의 --horizontal-pod-autoscaler-sync-period flag로 변경 가능.
...
- HPA는 metrics가 안정되도록 HPA event 후에 3분을 기다린 후에 scale-up event를 발생시킨다.
→ kube-controller-manage의 --horizontal-pod-autoscaler-upscale-delay flag로 변경 가능.
...
- HPA는 replica의 개수가 요동치는 변동을 겪지 않도록 HPA event 후에 5분을 기다린 후에 scaledown event를 발생 시킨다.
→ kube-controller-manage의 --horizontal-pod-autoscaler-downscale-delay flag로 변경 가능.
...
- HPA는 Deployment object에서 최적으로 동작한다. HPA에서 target으로 설정된 Deployment의
...
- replica를 직접적으로 수정하는 것은 바람직 하지 않다.
Custom Metrics를 사용하는 HPA
• autoscaling/v2alpha1 API object를 사용.
• 별도의 configuration 과정이 다수 필요.
• GKE에서는 Stackdriver adapter를 정식으로 지원.
• 이외의 환경에서는 Prometheus adapter를 사용해야 하지만 개발 상태는 초기 상태.
• application에서 Prometheus format으로 custom metrics를 expose 해야 한다.
나. VPA (Vertical Pod Autoscaler)
VPA Workflow
...
나-1. VPA 개요
- Pod의 CPU와 memory를 변경하여 할당.
- Pod의 restart되어 resource 변경.
- OOM(Out Of Memory) event에 반응.
- Pod에 할당할 수 있는 Min/Max resource를 설정 가능.
- 현재 alpha 개발 상태.
나-2. VPA Workflow
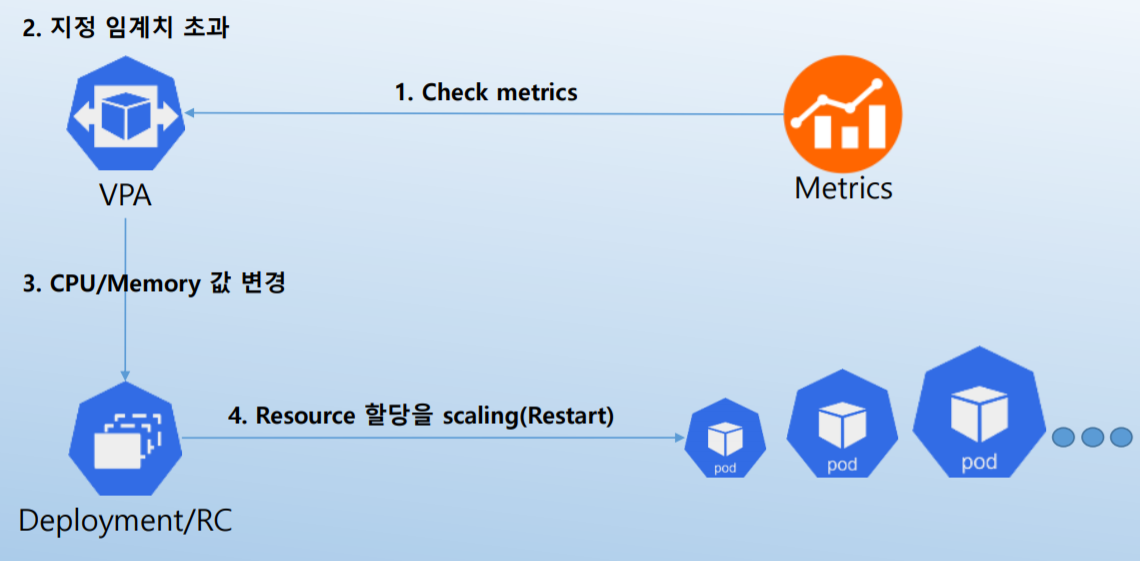
나-3. VPA에 대하여 알아야 할 것들
- VPA의 metrics check 간격은 10초.
- VPA의 변경으로 인해 모든 Pod들이 restart되는 것을 방지하기 위해 Pods Distribution Budget(PDB)가 반영.
- Pod를 restart하지 않고 resource를 변경할 수 없음.
→ Pod는 stop된 후에 새로 할당된 resource들을 기반으로 rescheduling된다. - VPA와 HPA는 아직 서로 호환되지 않으며 동일한 pod에서 동작되지 않는다.
→ cluster 내에서 이 둘을 사용하기 위해서는 구성할 때 사용범위를 확실하게 분리해야 한다. - VPA는 resource request만 조정하고 limit은 설정하지 않으므로 오동작하는 application이 resource를 잠식할 수 있음에 주의.
CA Workflow
...
다. CA (Cluster Pod Autoscaler)
다-1. CA 개요
- Pending pod들을 기반으로 cluster node들을 scaling.
- Cloud provider와 통신하여 node 증가 또는 idle node들의 회수를 진행
- 현재 GCP, AWS, Azure를 지원.
- Kubernetes 1.8 version에서 CA 1.0(G.A)이 release.
다-2. CA Workflow
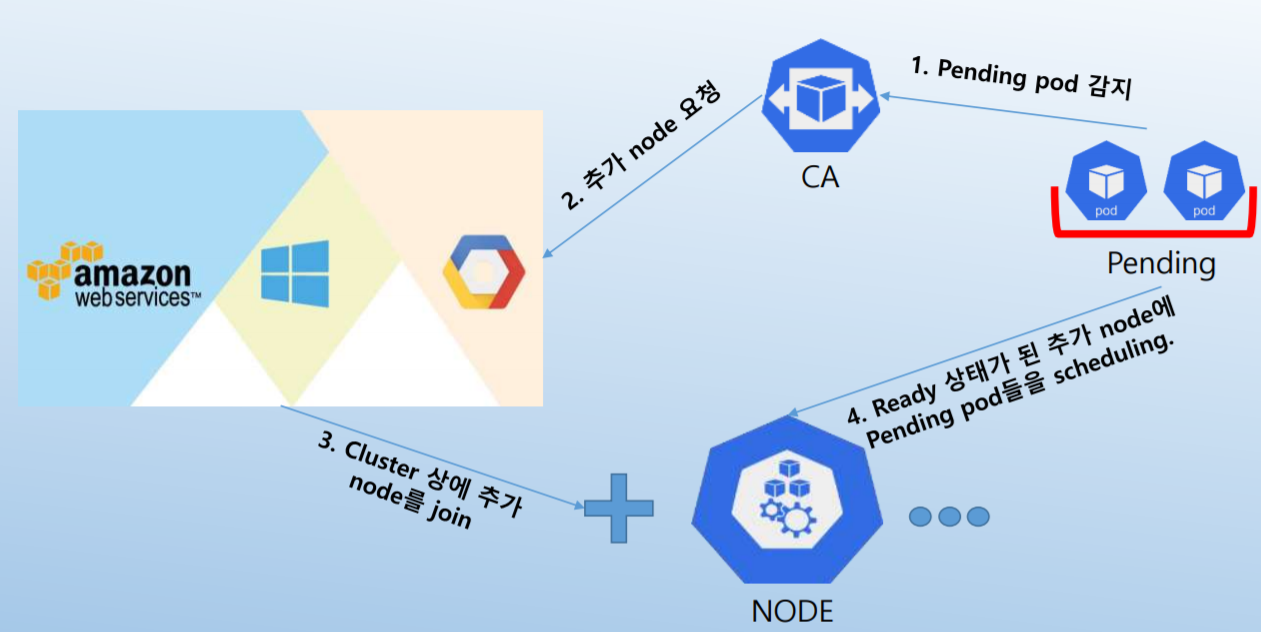
다-3. CA 대해 알아야 할 것들
- CA가 pending pod들을 check하는 간격은 10초이며 30초마다 필요한 추가 node를 계산.
- CA는 사용률이 높지 않은 node들의 scale down은 10분을 대기하고 수행.
- Annotation의 "cluster-autoscaler.kubernetes.io/safe-to-evict": "true".
→ 적절히 사용. 남용하여 대다수의 pod들이 사용되면 scale down에 대한 flexibility가 떨어짐. - scale down에서 pod들이 quorum을 유지하도록 PodDisruptionBudgets를 사용.
...
다-4. Autoscaler 결합 workflow
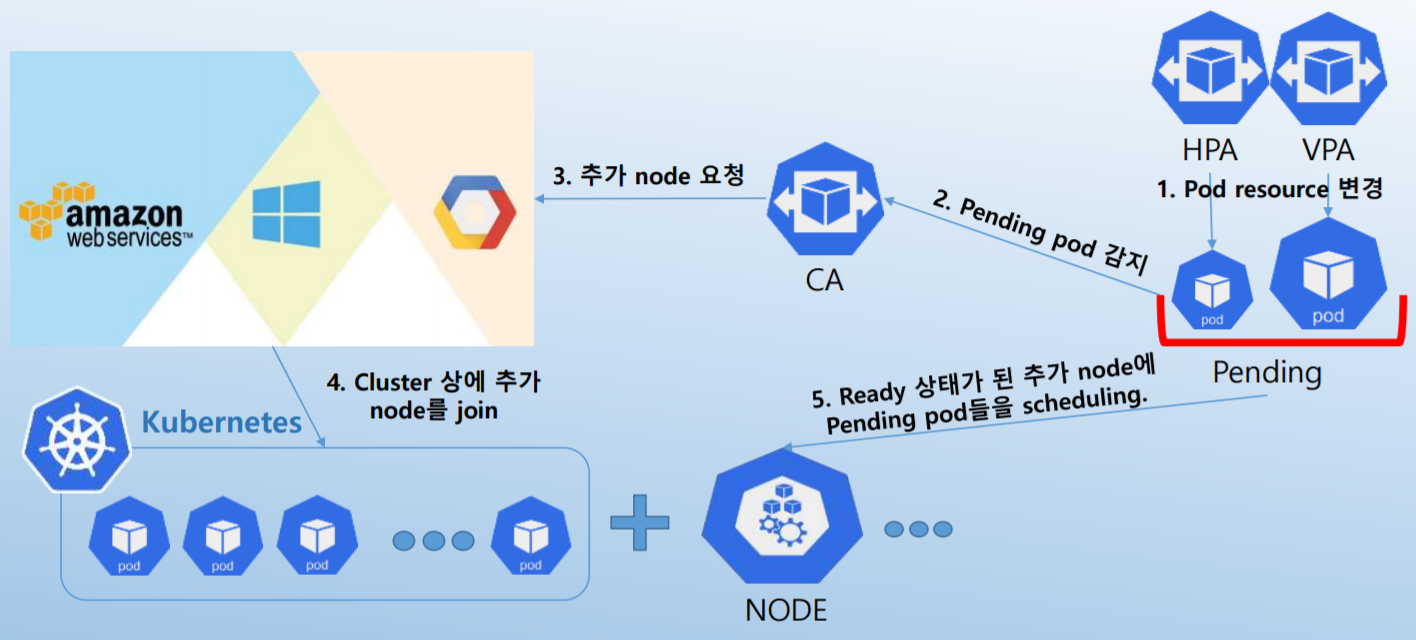
실제 동작
- CA에서 node를 join 시키는데는 시간이 발생.
→ AWS + kops 환경에서는 5분 정도의 시간이 발생. - Node resource가 여유가 있다면 HPA, VPA의 scaling은 수십초 내에 완료.
...