15장 : Auto-scaling of Pod and Cluster Node
| Info | ||
|---|---|---|
| ||
|
| Note |
|---|
FEATURE STATE: 힙스터에서 메트릭 가져오기는 Kubernetes 1.11에서 사용 중단(deprecated)됨. |
15.1 포드의 수평적 오토스케일링
Horizontal Pod Autoscaler는 어떻게 작동하는가?
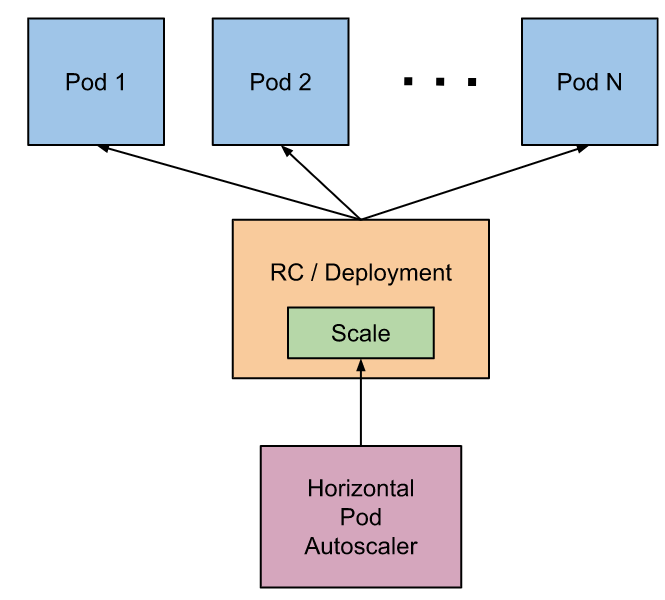
Horizontal Pod Autoscaler는 컨트롤러 관리자의 --horizontal-pod-autoscaler-sync-period 플래그(기본값은 15초)에 의해 제어되는 주기를 가진 컨트롤 루프로 구현된다.
각 주기 동안 컨트롤러 관리자는 각 HorizontalPodAutoscaler 정의에 지정된 메트릭에 대해 리소스 사용률을 질의한다. 컨트롤러 관리자는 리소스 메트릭 API(파드 단위 리소스 메트릭 용) 또는 사용자 지정 메트릭 API(다른 모든 메트릭 용)에서 메트릭을 가져온다.
15.1.1 오토스케일링 프로세스
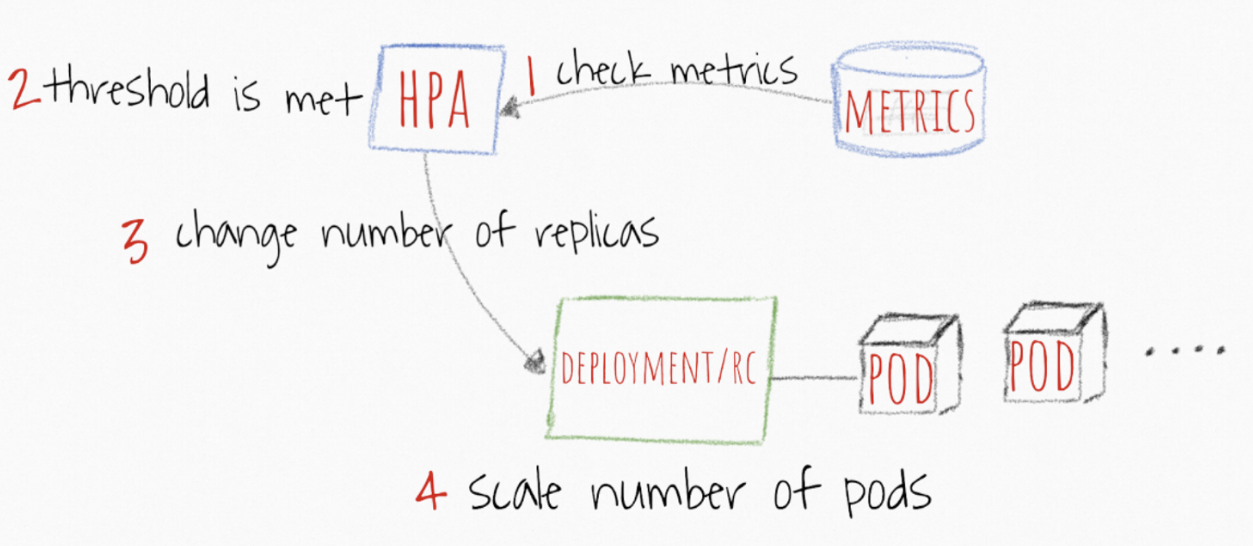
- HPA continuously checks metrics values you configure during setup AT A DEFAULT 15 SEC intervals
- HPA는 설치 중에 구성한 메트릭 값을 지속적으로 확인합니다. (기본 15 SEC 간격)
Info https://kubernetes.io/docs/tasks/debug-application-cluster/resource-metrics-pipeline/#metrics-server
- HPA attempts to increase the number of pods If the SPECIFIED threshold is met
- SPECIFIED 임계 값이 충족되면 HPA는 포드 수를 늘리려고합니다.
Info title 알고리즘 세부정보 가장 기본적인 관점에서, Horizontal Pod Autoscaler 컨트롤러는 원하는(desired) 메트릭 값과 현재(current) 메트릭 값 사이의 비율로 작동한다.
ceil[현재 레플리카 수 * ( 현재 메트릭 값 / 원하는 메트릭 값 )] = 원하는 레플리카 수[3 * 200m / 100m ] = 6 (복제본 수가 두 배가 된다.)[6 * 50m / 100m ] = 3 (복제본 수가 반이 된다.)
- HPA mainly updates the number of replicas inside the deployment or replication controller
- HPA는 배포 또는 복제 컨트롤러 내부의 복제본 수를 업데이트합니다.
- The Deployment/Replication Controller WOULD THEN roll-out ANY additional needed pods
- Deployment/Replication Controller 에서 추가로 필요한 포드를 롤아웃 합니다.
| Info | ||
|---|---|---|
| ||
|

오토스케일러 목록 조회
- kubectl get hpa
오토스케일러 상세 확인
- kubectl describe hpa
오토스케일러 삭제
- kubectl delete hpa
CLI를 통한 오토스케일러 설정
- kubectl autoscale rs foo --min=2 --max=5 --cpu-percent=80
Info title 오토스케일 명령어 https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands#autoscale